Введение в модель данных SQL
Раздел GROUP BY ROLLUP
Эти же результаты можно получить при выполнении единственного запроса, если в его формулировке использовать специальный вид группировки ROLLUP (пример 16.1):
SELECT DEPT_NO, EMP_BDATE, MAX (EMP_SAL) AS MAX_SAL FROM EMP GROUP BY ROLLUP (DEPT_NO, EMP_BDATE);
Пример 16.1.
(html, txt)
Сначала покажем, как будет выглядеть результирующая таблица этого запроса, а потом приведем развернутое пояснение действия новой конструкции. В результате выполнения запроса будет получена таблица, показанная на рис.16.1.
Как видно, в столбце MAX_SAL первой строки1) результирующей таблицы находится максимальное значение зарплаты служащих на всем предприятии. Столбцы DEPT_NO и EMP_BDATE в этой строке содержат неопределенное значение, поскольку значение MAX_SAL не привязано к каким-либо отделу и возрастной категории. В столбце MAX_SAL следующих трех строк находятся максимальные значения зарплаты сотрудников отделов с номерами 1, 2 и 3 соответственно, что показывают значения столбца DEPT_NO. Столбец EMP_BDATE в этих строках содержит неопределенное значение, поскольку значение MAX_SAL не привязано к какой-либо возрастной категории. Наконец, в столбце MAX_SAL в последних шести строках содержатся максимальные значения зарплаты сотрудников каждой возрастной категории каждого отдела, что показывают значения столбцов DEPT_NO и EMP_BDATE, которые теперь содержат соответствующий номер отдела и год рождения служащих.
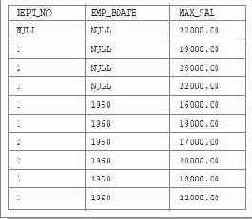
Рис. 16.1. Результат запроса с разделом GROUP BY ROLLUP
В общем случае пусть раздел группировки запроса имеет вид GROUP BY ROLLUP (cname1, cname2, ... , cnamen), где cnamei (i = 1, 2, ... , n) - имя столбца таблицы-результата раздела FROM запроса. Пусть в списке выборки используются вызовы агрегатных функций AGG1, AGG2, ... , AGGm над значениями столбцов, не входящих в список группировки, а также имена столбцов cname1, cname2, ... , cnamen. Тогда запрос выполняется следующим образом. Первая строка результата (первый набор строк результирующей таблицы) производится таким образом, как если бы в запросе вообще отсутствовал раздел GROUP BY, т.е. агрегатные функции AGG1, AGG2, ... , AGGm вычисляются над значениями всех строк таблицы. Значением столбцов cname1, cname2, ... , cnamen в этой строке является NULL. (i+1)-й набор строк результата формируется так, как если бы раздел группировки запроса имел вид GROUP BY (cname1, cname2, ... , cnamei) (1

Может показаться, что запросы, содержащие раздел GROUP BY ROLLUP, настолько сложны, что их выполнение будет занимать чрезмерно большое время. Это ощущение является ложным. В действительности, при выполнении запросов с обычной группировкой вида GROUP BY cname1, cname2, ... , cnamen, как правило, последовательно выполняется сортировка строк таблицы-результата раздела FROM в соответствии со значениями столбца cname1, затем - в соответствии со значениями столбца cname2 и т. д., и в заключение - сортировка в соответствии со значениями столбца cnamen. Во время выполнения каждой сортировки можно заодно вычислять значения агрегатных функций. Так что стоимость выполнения запроса, содержащего раздел GROUP BY ROLLUP, лишь незначительно отличается от стоимости выполнения запроса с обычной группировкой.